AWS presenta esquemas de alta disponibilidad para Amazon RDS denominado Multi-AZ donde se pueden tener una o dos instancias de base de datos en espera, aprovechando la Infraestructura global de AWS que cuenta con zonas de disponibilidad, donde los clientes pueden desplegar sus cargas de trabajo en varias zonas de disponibilidad dentro una región y de esta forma incrementar la tolerancia a fallos. Cuando la implementación tiene una instancia de base de datos en espera, se denomina implementación de instancia de base de datos Multi-AZ. Cuando la implementación tiene dos instancias de base de datos en espera, se denomina implementación de clúster de base de datos Multi-AZ.
A continuación, vamos a detallar cada una de estas implementaciones.
Implementaciones de instancias de base de datos Multi-AZ
Una implementación de instancia de base de datos Multi-AZ crea de manera automática una instancia de base de datos (DB) principal y una réplica en una AZ diferente, donde de manera sincrónica mantiene actualizados los datos en ambas instancias. Cuando se detecta un error, Amazon RDS conmuta por error automáticamente a una instancia en espera sin necesidad de intervención manual. Esta réplica no sirve para tráfico de lectura.
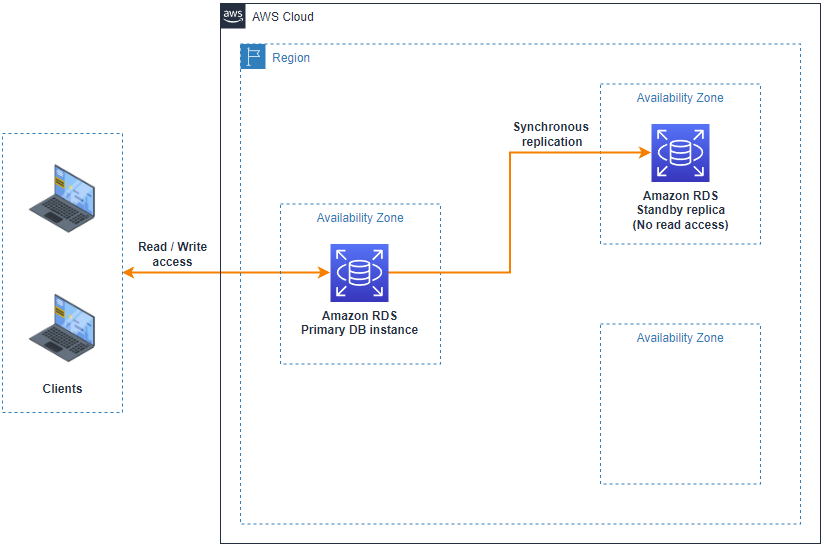
Figura 1 – Arquitectura implementación de instancia de base de datos Multi-AZ
Cómo sería una arquitectura apropiada para un esquema de Alta disponibilidad de RDS?
En el siguiente ejemplo se tiene una zona de alta disponibilidad a y b, donde en cada una se despliega un servidor de aplicación y se tiene una base de datos de RDS, para esto se debe crear un grupo de auto escalamiento que sea capaz de crecer o reducirse para tener solicitudes de acuerdo con la demanda, adicionalmente se debe agregar un balanceador de carga para que distribuya las solicitudes de acuerdo con el tráfico y al procesamiento que tienen los servidores de aplicación. En el caso de falla de un servidor de aplicaciones inmediatamente se crea uno nuevo y la aplicación continua disponible, pero si fallara la base de datos RDS la aplicación ya no quedaría disponible. Ver Figura 2.
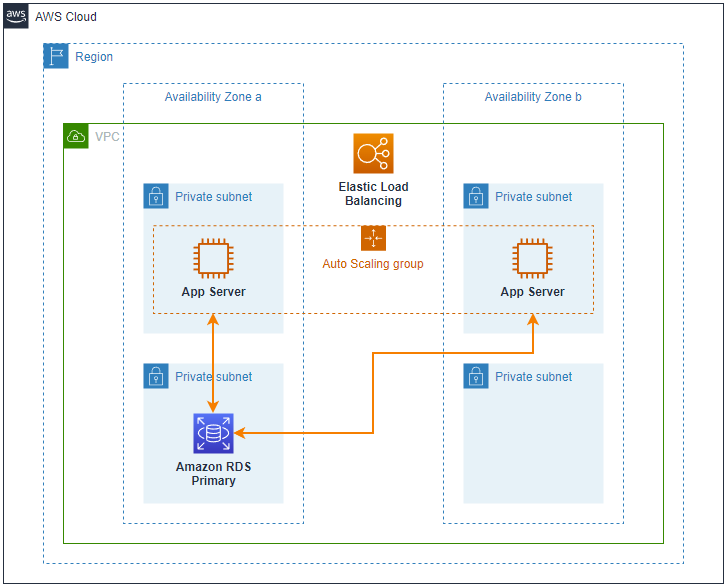
Figura 2 – Implementación de instancia de base de datos Multi-AZ
Para solucionar esta situación con la base de datos, AWS ha incorporado una opción de alta disponibilidad que se puede habilitar desde la consola de administración activando el despliegue multi AZ o en diferentes zonas de disponibilidad, también se pude utilizar AWS CLI o la API de Amazon RDS, esta opción crea una instancia secundaria de base de datos exactamente igual a la primaria con el mismo tipo de instancia y configuración de volumen EBS en otra zona de disponibilidad, luego se configura la replicación síncrona manteniendo un duplicado exacto de los datos en la réplica en espera. Ver Figura 3.
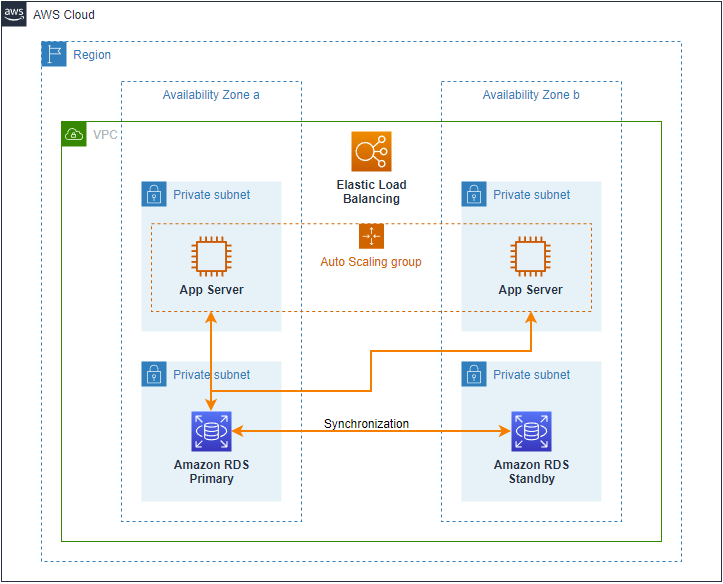
Figura 3 – Implementación de instancia de base de datos Multi-AZ
Si la instancia primaria de RDS falla, el monitor de Amazon RDS asignará como primaria la instancia que está en espera hasta que la primaria original se recupere y las solicitudes de los servidores de aplicación se redireccionará a la nueva instancia de base de datos primaria. Ver Figura 4.
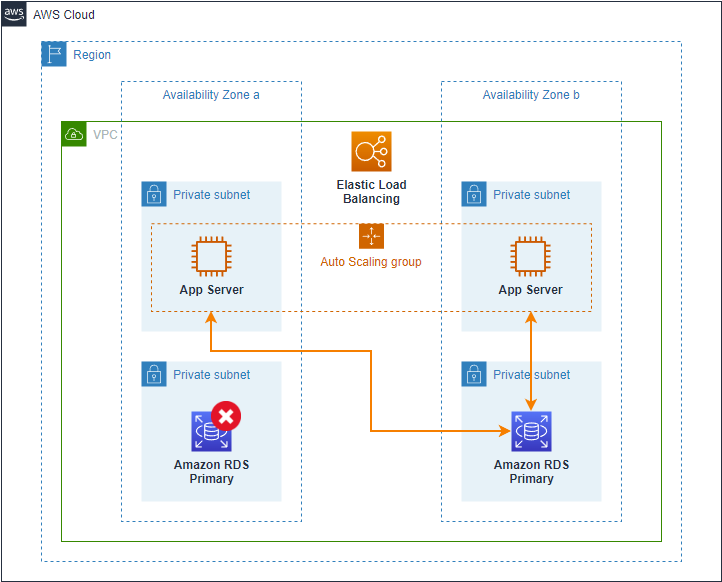
Figura 4 – Implementación de instancia de base de datos Multi-AZ
Implementaciones de clústeres de base de datos Multi-AZ
Una implementación de clúster de base de datos Multi-AZ es un modo de implementación de alta disponibilidad de Amazon RDS con dos instancias de base de datos en espera legibles. Un clúster de base de datos Multi-AZ tiene una instancia de base de datos de escritor y dos instancias de base de datos de lector en tres zonas de disponibilidad separadas en la misma región de AWS. Los clústeres de base de datos Multi-AZ brindan alta disponibilidad, mayor capacidad para cargas de trabajo de lectura y menor latencia de escritura en comparación con las implementaciones de instancias de base de datos Multi-AZ.
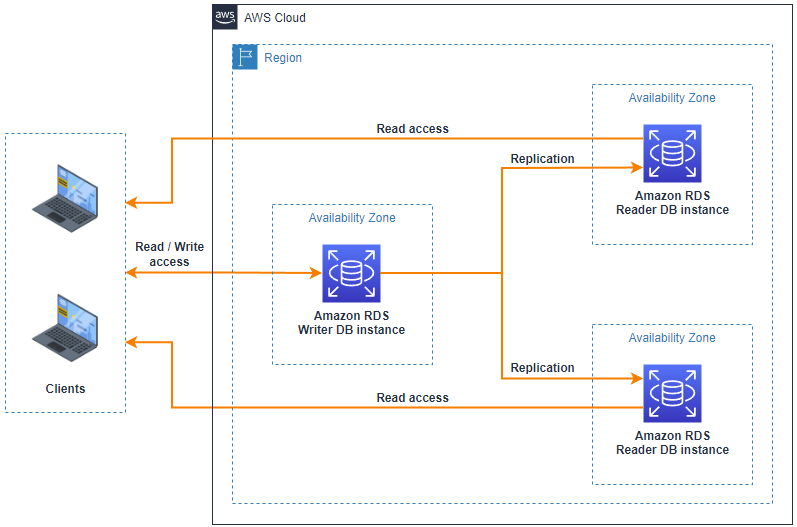
Figura 5 – Arquitectura de clúster de base de datos Multi-AZ
Con un clúster de base de datos Multi-AZ, Amazon RDS replica datos de la instancia de base de datos del escritor en ambas instancias de base de datos del lector mediante las capacidades de replicación nativas del motor de la base de datos. Cuando se realiza un cambio en la instancia de base de datos del escritor, se envía a cada instancia de base de datos del lector. Se requiere el reconocimiento de al menos una instancia de base de datos de lector para que se confirme un cambio.
Las instancias de Reader DB actúan como objetivos de conmutación por error automáticos y también sirven tráfico de lectura para aumentar el rendimiento de lectura de las aplicaciones. Si se produce una interrupción en la instancia de base de datos de escritor, RDS administra la conmutación por error a una de las instancias de base de datos de lector. RDS hace esto en función de qué instancia de base de datos del lector tiene el registro de cambios más reciente.
Los clústeres de base de datos Multi-AZ suelen tener una latencia de escritura más baja en comparación con las implementaciones de instancias de base de datos Multi-AZ. También permiten que las cargas de trabajo de solo lectura se ejecuten en instancias de base de datos de lectores. La consola de RDS muestra la zona de disponibilidad de la instancia de base de datos del escritor y las zonas de disponibilidad de las instancias de la base de datos del lector. Actualmente, los clústeres de base de datos Multi-AZ solo están disponibles en algunas regiones de AWS.
Para tener en cuenta algunas consideraciones, ver la siguiente tabla comparativa.
Tabla comparativa
|
Característica |
Single-AZ | Multi-AZ con una instancia en espera | Multi-AZ con dos instancias en espera legibles |
| Motores disponibles |
|
|
|
| Capacidad adicional de lectura | Ninguna: la capacidad de lectura se limita a su instancia principal. | Ninguna: su instancia de base de datos en espera es solo un destino de conmutación por error pasivo para alta disponibilidad. |
|
| Latencia inferior (mayor rendimiento) para confirmaciones de transacción | Confirmaciones de transacción hasta dos veces más rápidas en comparación con Multi-AZ de Amazon RDS con una instancia en espera. | ||
| Duración de conmutación por error automática |
|
|
|
| Mayor resiliencia a una interrupción de AZ | Ninguna: en caso de un error de AZ, se arriesga a perder datos y horas en tiempo de conmutación por error. | En caso de un error de AZ, su carga de trabajo conmutará por error automáticamente a la instancia en espera actualizada. | En caso de error, una de las dos instancias en espera restantes tomará el control y servirá a la carga de trabajo (escrituras) desde la instancia principal. |
Capa gratuita de base de datos de AWS
|
|
La capa gratuita de AWS ofrece a los usuarios la oportunidad de explorar productos de forma gratuita, con ofertas que incluyen productos que siempre son gratuitos, gratuitos durante 12 meses y pruebas gratuitas a corto plazo. AWS ofrece la selección más amplia de bases de datos especialmente diseñadas, lo que le permite ahorrar, crecer e innovar más rápido. Cree soluciones de bases de datos utilizando estas ofertas de productos de la capa gratuita de AWS. |
Para obtener información actualizada de los servicios de base de datos de AWS los invito a seguir su página “AWS Databases & Analytics” en Linkedin.
Espero esta información sea de utilidad !!
Compartir:
Síguenos: