En la actualidad, contamos con diversas opciones para alojar bases de datos, donde tenemos un primer escenario que sería nuestro datacenter corporativo u on-premises donde contamos con una infraestructura a nivel de hardware, servidores, redes, etc y allí instalamos y configuramos nuestro motor de base de datos y creamos una o muchas instancias de nuestro motor de base de datos donde finalmente creamos o migramos nuestras bases de datos corporativas. Sin embargo, este enfoque puede tener implicaciones significativas en términos de rendimiento, operatividad y costos, y en actualidad se realizan muchas implementaciones de este tipo.
Una vez aparece el concepto de virtualización y posteriormente el de la nube, surge un segundo escenario que combina ambas tecnologías (Virtualización & Cloud) donde a través de un proveedor de nube como AWS podemos crear y configurar máquinas virtuales y es allí donde instalamos y configuramos nuestro motor de bases de datos y alojamos nuestras bases de datos corporativas, donde finalmente nos olvidamos de adquirir hardware costoso y podemos adquirir los beneficios que nos provee la nube de AWS como escalabilidad y la elasticidad. Este escenario también lo conocemos como Infraestructura como servicio (IaaS).
Las tecnologías de nube de AWS siguen evolucionando y surge un tercer escenario que utiliza toda la magia de la nube y es lo conocemos como plataforma como servicio (PaaS), donde AWS provee soluciones nativas de nube y en el caso de las bases de datos es lo que conocemos como bases de datos como servicio, brindándonos muchos beneficios como eliminándonos la necesidad de administrar hardware y sistemas operativos ya que esto lo vendría realizando AWS. Adicional a este beneficio no tenemos que preocuparnos por el aprovisionamiento de recursos, por planificar la capacidad, por el mantenimiento del hardware, por la instalación de parches o actualizaciones ya que AWS hace todo esto por nosotros y nos ayuda con muchas otras tareas lo que se traduce en una mayor eficiencia y rendimiento de las bases de datos.

Entrando ya en contexto, en este artículo nos concentraremos en el servicio nativo de base de datos relacional de AWS llamado Amazon Aurora.
Amazon Aurora es un servicio nativo de bases de datos relacional desarrollado por AWS en Octubre de 2014, que se encuentra disponible bajo el esquema de bases de datos relaciones (RDS). Cuando se lanzo el servicio al mercado, AWS ofreció inicialmente un servicio compatible con MySQL y a medida que el servicio fue evolucionando, en Octubre de 2017 agrego la compatibilidad con PostgreSQL, teniendo dos sistemas de gestión de bases de datos de código abierto ampliamente utilizados. Con esta compatibilidad Amazon Aurora puede ofrecer hasta cinco veces el rendimiento de MySQL y hasta tres veces el rendimiento de PostgreSQL sin necesidad de realizar mayores cambios en su configuración.

Durante esta evolución a parte de la compatibilidad con MySQL y PostgreSQL, se incluyeron características relevantes como:
- Aurora Fast Cloning (copia en escritura) que permite a los clientes crear copias de sus bases de datos. Agosto 2017.
- Aurora Backtrack, que permite a los desarrolladores rebobinar clústeres de bases de datos sin crear uno nuevo. Mayo 2018.
- Versión de Aurora sin servidor. Agosto 2018.
- Habilitar la posibilidad de detener e iniciar clusters de Amazon Aurora. Septiembre 2018.
¿Por qué AWS desarrollo Amazon Aurora?
La razón principal del porque AWS desarrollo Amazon Aurora, era la de afrontar los desafíos comunes que tienen las bases de datos relacionales tradicionales en términos de rendimiento, escalabilidad y disponibilidad, donde el objetivo principal es proporcionar a los clientes una solución de base de datos relacional altamente escalable, duradera y de alto rendimiento en la nube.
Este desafío motivó a los desarrolladores de AWS para crear Amazon Aurora, a lo cual se unieron otros desafíos como reducir el tiempo de inactividad durante las actualizaciones, mejorar los problemas de rendimiento con cargas de trabajo intensivas y mejorar la dificultad para escalar en función de la demanda con la finalidad de brindar una experiencia de usuario sin interrupciones aprovechando la potencia de la infraestructura de la nube de AWS.
Este esfuerzo se reflejó en una solución que ofrece una mayor capacidad de rendimiento y escalabilidad, al tiempo que garantizara una alta disponibilidad y durabilidad de los datos.
Características y beneficios de Amazon Aurora
- Un rendimiento hasta 5 veces superior al de MySQL y 3 veces superior al de PostgreSQL: Aurora utiliza una variedad de técnicas de software y hardware para garantizar que el motor de base de datos pueda utilizar completamente el proceso, la memoria y las redes disponibles.
- Configuración sin servidor: es una configuración de escalado automático bajo demanda, en la que las bases de datos se inician, se apagan y escalan automáticamente la capacidad hacia arriba o hacia abajo en función de las necesidades de las aplicaciones.
- Escalado automático de almacenamiento: Amazon Aurora escala automáticamente la E/S para satisfacer las necesidades de las aplicaciones más exigentes. También aumenta el tamaño del volumen de la base de datos a medida que crecen las necesidades de almacenamiento. El volumen se expande en incrementos de 10 GB hasta un máximo de 128 TiB.
- Implementaciones Multi-AZ con réplicas de Amazon Aurora: En caso de error de instancia, Amazon Aurora utiliza la tecnología Multi-AZ de Amazon RDS para automatizar la conmutación por error a una de las hasta 15 réplicas de Aurora que ha creado en tres zonas de disponibilidad.
- Base de datos global de Amazon Aurora: Para las aplicaciones distribuidas globalmente, se puede utilizar una base de datos global de Aurora, donde una sola base de datos de Aurora puede abarcar varias regiones de AWS para permitir lecturas locales rápidas y una rápida recuperación ante desastres.
- Copias de seguridad automáticas, continuas e incrementales y restauración puntual: La capacidad de copia de seguridad de Amazon Aurora permite la recuperación a un momento dado de la instancia. Esto permite restaurar la base de datos a cualquier segundo durante su período de retención, hasta los últimos 5 minutos. El período de retención automática de la copia de seguridad se puede configurar hasta 35 días.
- Integración con el ecosistema de AWS: Amazon Aurora se integra fácilmente con otros servicios de AWS, lo que facilita la construcción de aplicaciones escalables y altamente disponibles. Se puede combinar con servicios como Amazon RDS, AWS Lambda, Amazon CloudWatch, entre otros, para obtener una solución completa y optimizada en la nube.
- Administración simplificada: AWS se encarga de tareas de administración como el aprovisionamiento de recursos, el mantenimiento del hardware, las copias de seguridad y las actualizaciones de software. Esto permite a los usuarios enfocarse en las aplicaciones y en los datos, sin tener que preocuparse por la infraestructura subyacente.
- Costos optimizados: Amazon Aurora ofrece un rendimiento superior a las bases de datos tradicionales a un costo significativamente menor. Además, la capacidad de escalar hacia arriba o hacia abajo según la demanda permite un uso eficiente de los recursos y una mayor optimización de costos.
Arquitectura de Amazon Aurora
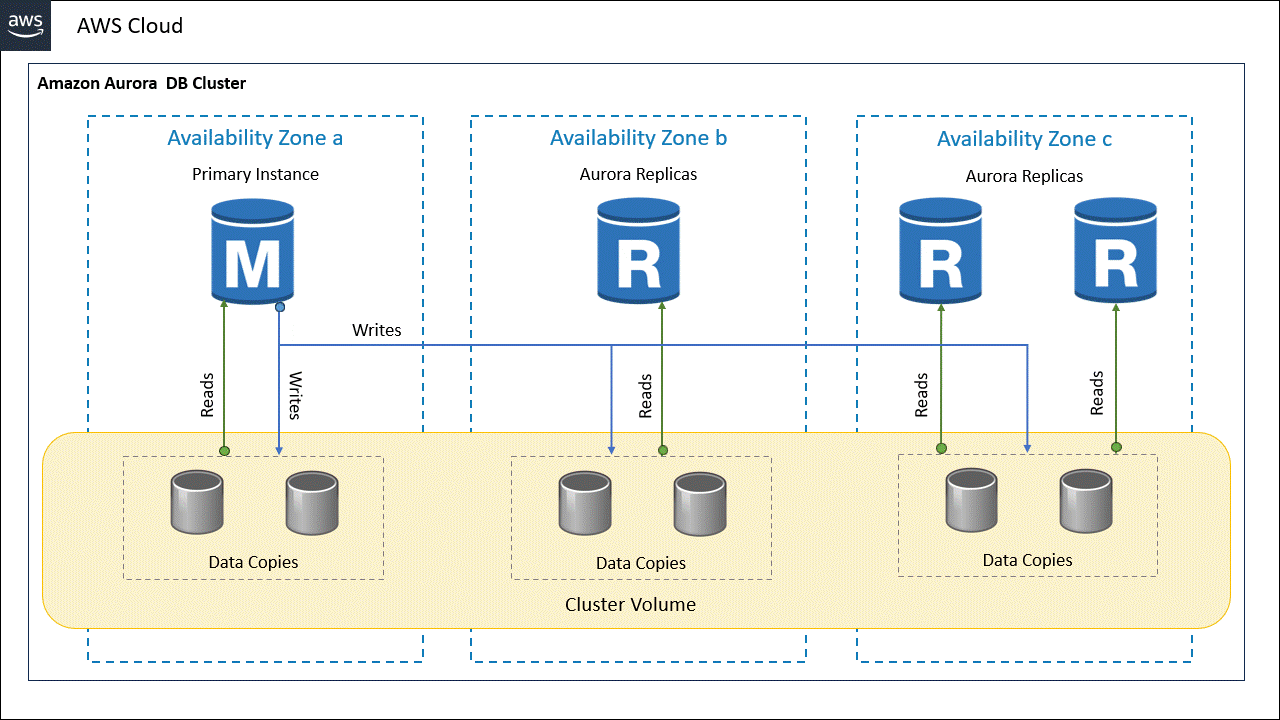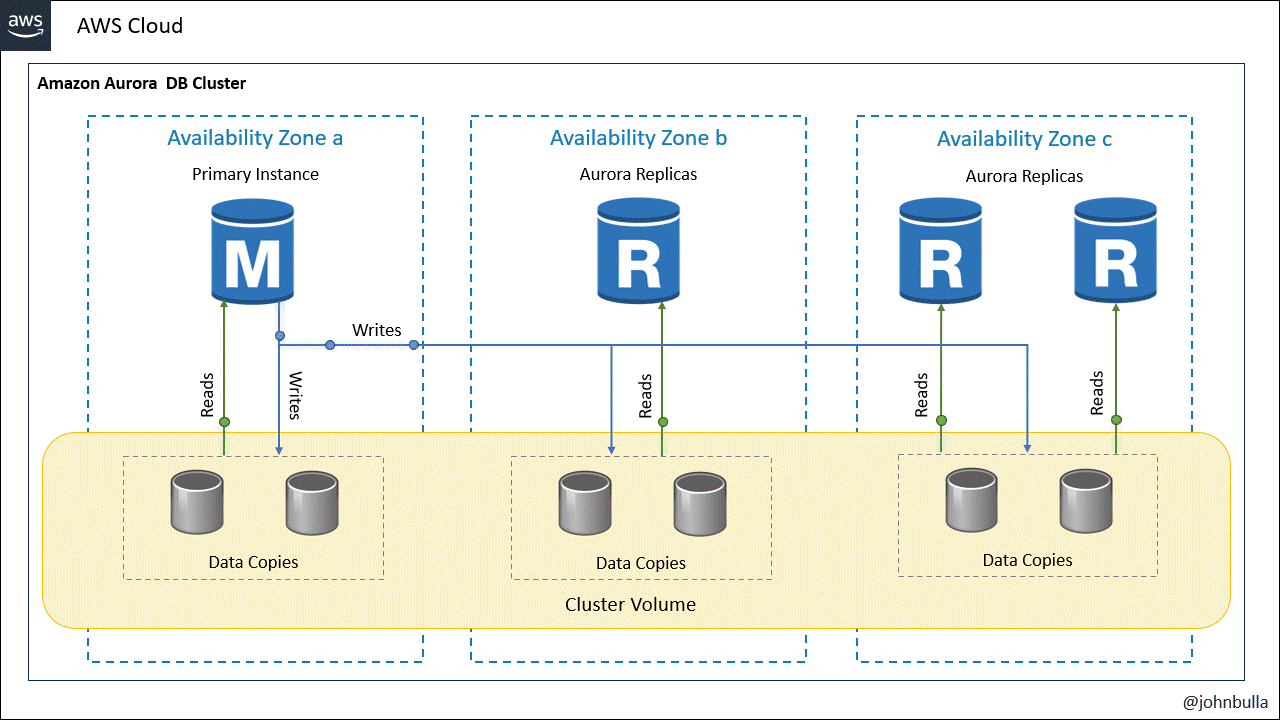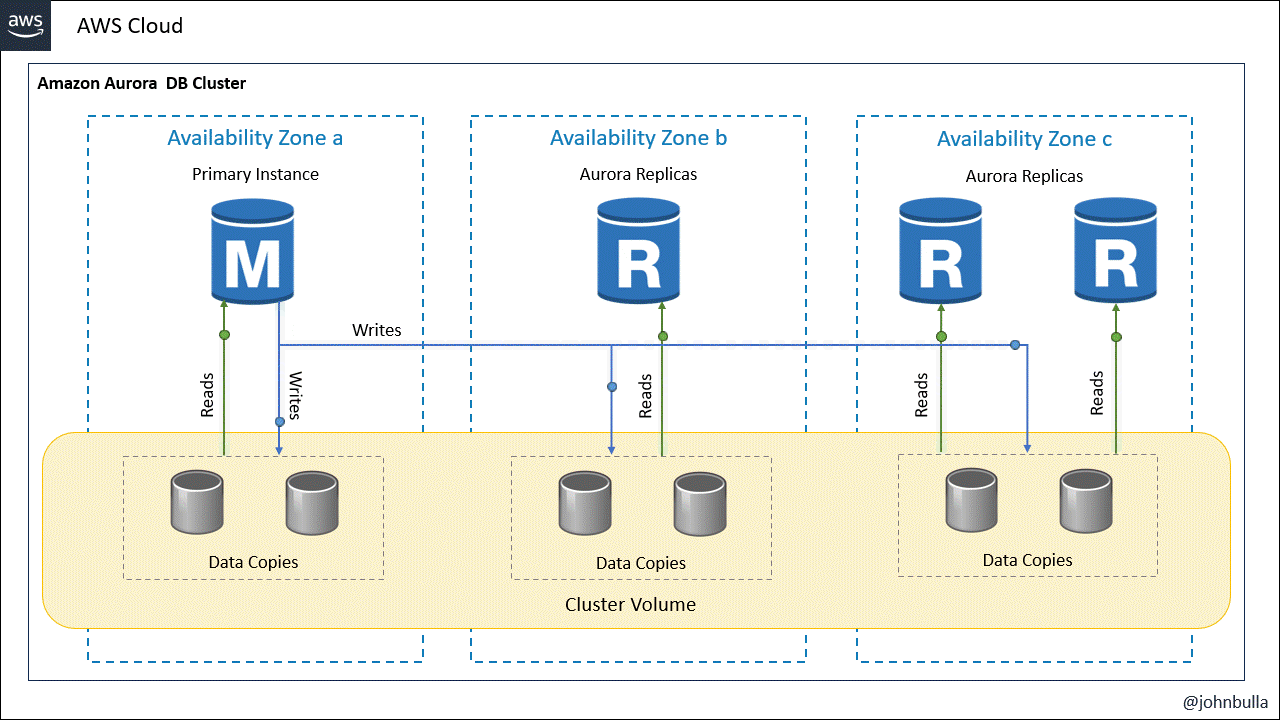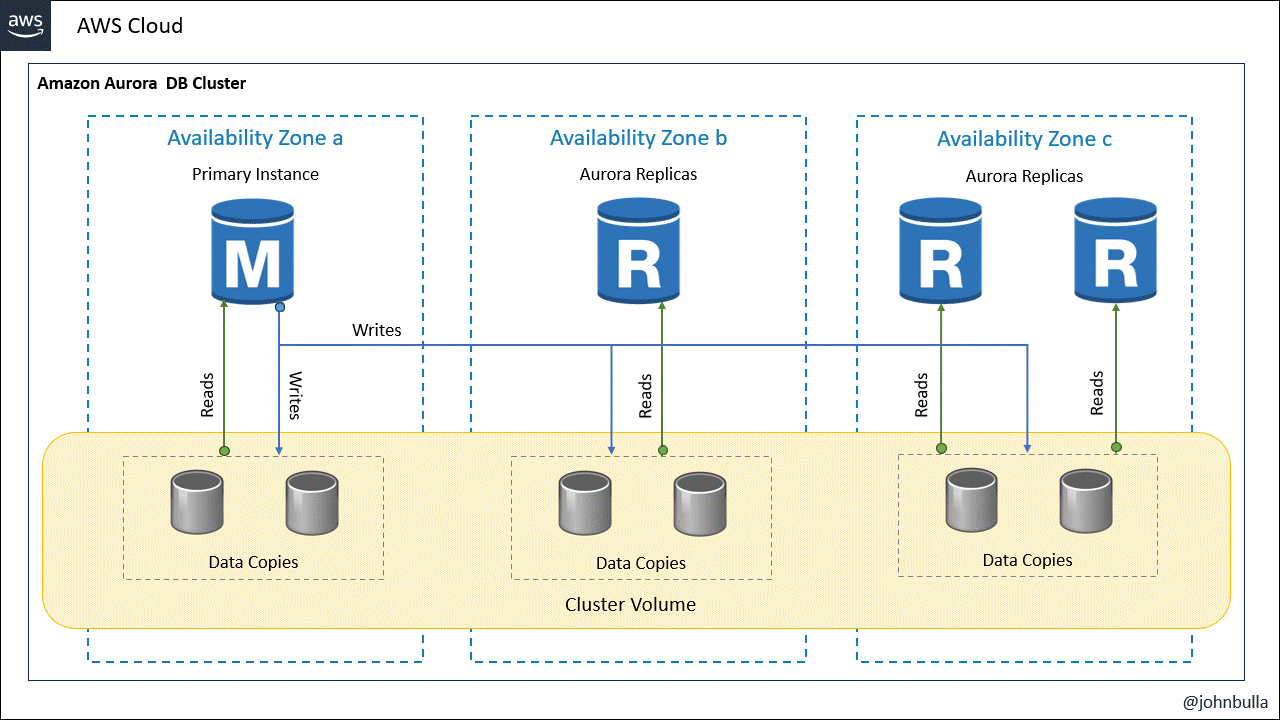
La arquitectura básica de Amazon Aurora comprende un clúster de base de datos de Amazon Aurora, que consiste en una colección de instancias de base de datos que funcionan juntas para proporcionar redundancia, disponibilidad y rendimiento mejorado. El clúster de base de datos de Amazon Aurora está diseñado para ser compatible con MySQL y PostgreSQL, y ofrece una compatibilidad nativa con estas bases de datos, lo que facilita la migración de aplicaciones existentes. El clúster de Aurora está compuesto por los siguientes componentes:
- Instancias de base de datos: Existen dos tipos de instancias o nodos que son la instancia de base de datos principal que admite operaciones de lectura y escritura y realiza todas las modificaciones de los datos en el volumen de clúster.
- Replicas: Son instancias de base de datos de Amazon Aurora que se conectan al mismo volumen de almacenamiento que la instancia de base de datos principal pero solo admite operaciones de lectura.
- Volumen de clúster: Un volumen de clúster de Aurora es un volumen de almacenamiento de base de datos virtual que abarca varias zonas de disponibilidad, de modo que una de esas zonas tiene una copia de los datos del clúster de bases de datos, lo que garantiza una alta velocidad de lectura y escritura con baja latencia.
Cada clúster de bases de datos Aurora debe tener una instancia de base de datos principal y puede tener hasta 15 instancias de base de datos de réplica.
De acuerdo con esta estructura, un clúster de Amazon Aurora muestra claramente la separación de la capacidad informática y el almacenamiento.
Una de las características distintivas de Amazon Aurora DB Clústeres es su arquitectura distribuida y su replicación automática y sincrónica en múltiples zonas de disponibilidad.
Conclusión
En resumen, AWS desarrolló Amazon Aurora para proporcionar a los clientes una base de datos relacional altamente eficiente, escalable y confiable en la nube, que pudiera superar los desafíos comunes asociados con las bases de datos tradicionales. Amazon Aurora brinda beneficios como alto rendimiento, escalabilidad automática, alta disponibilidad, administración simplificada, compatibilidad con MySQL y PostgreSQL, integración con el ecosistema de AWS y costos optimizados, lo que la convierte en una opción atractiva para muchas aplicaciones y empresas que buscan una base de datos confiable y eficiente en la nube.
Capa gratuita de base de datos de AWS
|
|
La capa gratuita de AWS ofrece a los usuarios la oportunidad de explorar productos de forma gratuita, con ofertas que incluyen productos que siempre son gratuitos, gratuitos durante 12 meses y pruebas gratuitas a corto plazo. AWS ofrece la selección más amplia de bases de datos especialmente diseñadas, lo que le permite ahorrar, crecer e innovar más rápido. Cree soluciones de bases de datos utilizando estas ofertas de productos de la capa gratuita de AWS. |

Para obtener información actualizada de los servicios de base de datos de AWS los invito a seguir su página “AWS Databases & Analytics” en Linkedin.
Espero esta información sea de utilidad.
Saludos,
Síguenos: