
Introducción
La inteligencia artificial está entrando en una nueva etapa con la llegada de los agentes inteligentes que son sistemas o entidades de software capaces de razonar, planificar y ejecutar tareas de manera autónoma. En este contexto surge el concepto de multiagentes, un enfoque donde varios agentes colaboran entre sí, intercambiando información y coordinando acciones para resolver problemas complejos de forma más eficiente y escalable.
Amazon Bedrock facilita la creación e implementación de este tipo de arquitecturas gracias a su servicio de Agents for Bedrock, que permite orquestar múltiples agentes basados en modelos fundacionales de AWS y de terceros. A través de esta plataforma, los desarrolladores y especialistas de IA pueden integrar fácilmente capacidades de lenguaje, razonamiento, ejecución de funciones y acceso a datos empresariales, construyendo soluciones de IA autónomas listas implementar en entornos de producción sin necesidad de gestionar infraestructura compleja.
Orquestar multi-agentes en Amazon Bedrock
El objetivo de este demo es crear cuatro agentes especializados, cada uno enfocado en un dominio específico de la organización: Recursos Humanos, Finanzas, TI y Legal. Estos agentes estarán diseñados para responder preguntas y proporcionar información relacionada con las políticas corporativas de su respectiva área. La coordinación entre ellos estará a cargo de un agente supervisor, responsable de recibir las solicitudes del usuario, identificar el tema correspondiente y dirigir la consulta al agente especializado adecuado.
Los promtps y las base de conocimiento se pueden consultar en el Github donde se encuentra desplegado el demo.
- Preparación de la base de conocimiento
El primer paso es preparar los datos en con la información de las políticas corporativas de cada una de áreas en archivos TXT y almacenarlos en un bucket de S3:
- Políticas Corporativas – RRHH
- Políticas Corporativas – Legal
- Políticas Corporativas – Finanzas
- Políticas Corporativas – IT
Ahora debemos crear un bucket de propósito general en AWS S3 para almacenar estos archivos que posteriormente serán utilizados por los agentes especializados como base de conocimiento.
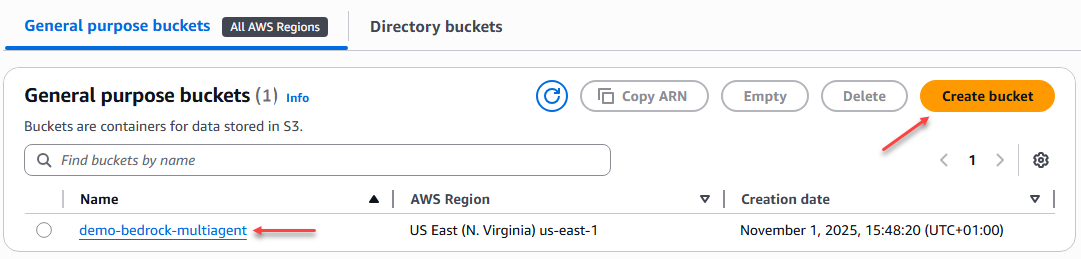
Figura 1 – Creación bucket S3
Posteriormente, se crean las carpetas correspondientes a cada área, donde se cargarán los archivos TXT que contienen la información de las políticas corporativas. Estos archivos conforman la base de conocimientos de cada agente especializado, permitiéndoles acceder al contenido relevante para responder de manera precisa a las consultas del usuario.
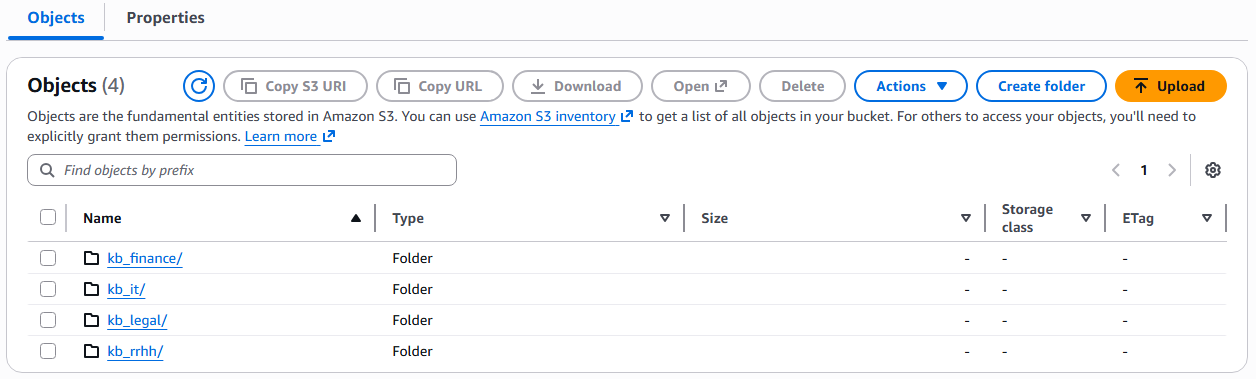
Figura 2 – Creación carpetas en el bucket S3
Cargamos los 4 archivos TXT en sus respectivas carpetas.
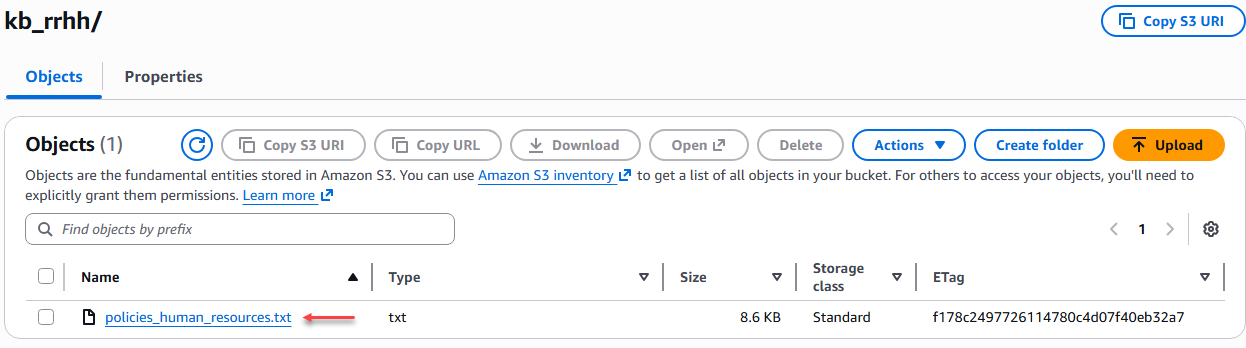
Figura 3 – Cargue de los archivos TXT.
- Crear bucket tipo vector (Preview)
En una arquitectura de IA agéntica, los agentes no solo ejecutan instrucciones, sino que razonan y buscan información contextual para dar respuestas más precisas. Para lograrlo, necesitan acceder a una base de conocimientos estructurada y semánticamente indexada, y ahí es donde entra el almacenamiento vectorial. El bucket vectorial es la memoria de los agentes, donde almacenan y consultan información relevante de manera eficiente. Sin él, los agentes solo podrían depender del conocimiento general del modelo fundacional, sin acceso al contexto específico de la empresa o del dominio que deben manejar. Existen otras alternativas para manjar el almacenamiento vectorial como lo pueden ser Amazon OpenSearch Serverless, o Amazon Aurora PostgreSQL con pgvector.
Los buckets vectoriales de S3 están optimizados para el almacenamiento duradero y rentable de grandes conjuntos de datos a largo plazo, manteniendo un rendimiento de consulta inferior a un segundo. Esta función se encuentra actualmente en versión preliminar y no recomendamos su uso en entornos de producción.
En Amazon S3 buscamos la opción de “Vector buckets” e iniciamos el proceso de creación de este.
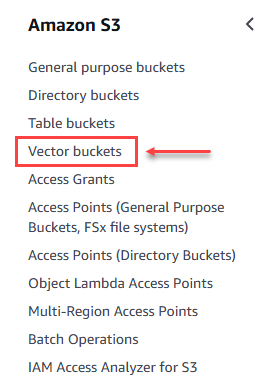
Figura 4 – Opción para crear Buckets vectoriales.
Iniciamos con la creación del bucket de tipo vector agregando un nombre.
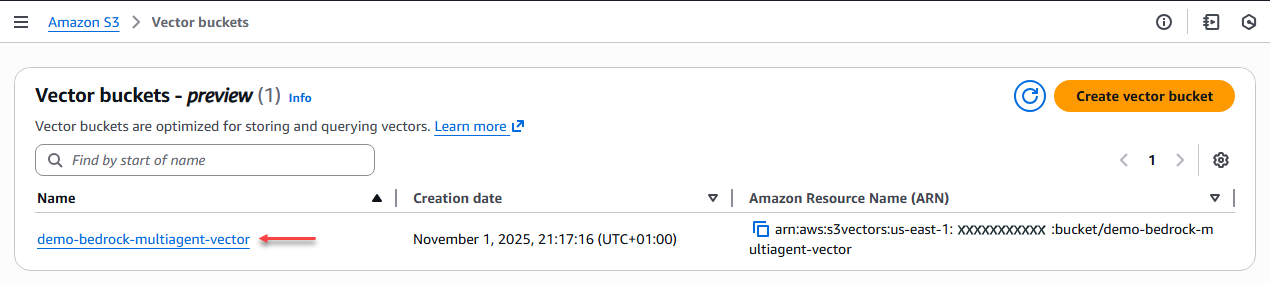
Figura 5 – Creación bucket vectorial.
El siguiente paso es crear los índices del para cada una de las áreas de la base de conocimientos que son Finanzas, Legal, IT y Recursos Humanos, para todo aplicamos la misma configuración:
Índices Base conocimientos de políticas
- Nombre índice vector: [kb-index-finance] – [kb-index-it] – [kb-index-legal] – [kb-index-rrhh]
- Dimensión: 1024
- Métrica de distancia: Coseno
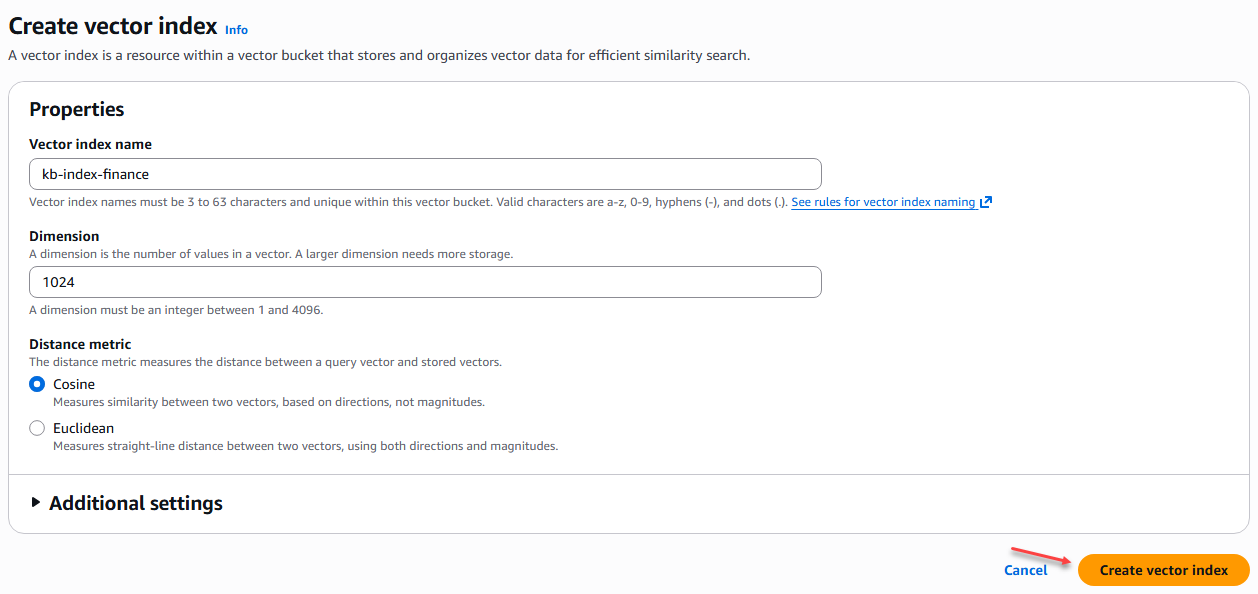
Figura 6 – Creación de un índice en el bucket vectorial
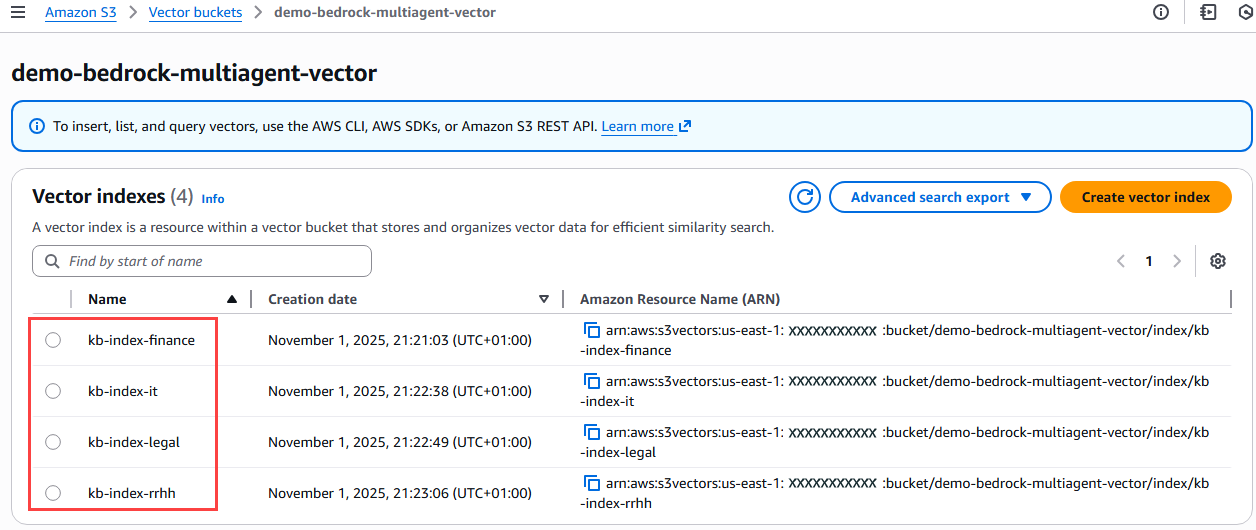
Figura 7 – Verificación índices creados en el bucket vectorial
- Creación de la base de conocimiento en Amazon Bedrock
En este paso crearemos las bases de conocimiento con la información de cada una de las áreas de empresa (Finanzas, IT, Legal, RRHH) que hemos tomado para este ejercicio, donde elegiremos tipo de almacenamiento “Amazon S3 vector” que creamos previamente.
En el menú de la izquierda de Amazon Bedrock, seleccionamos la opción “Build” à ”Knowledge Bases”.
En el momento de crear una base de conocimiento se nos pregunta si queremos la queremos crear con datos estructurados o no estructurados. En este caso seleccionamos la opción “Knowledge Base with vector store”
En el primer paso de creación de la base de conocimientos donde proporcionamos detalles como el nombre:
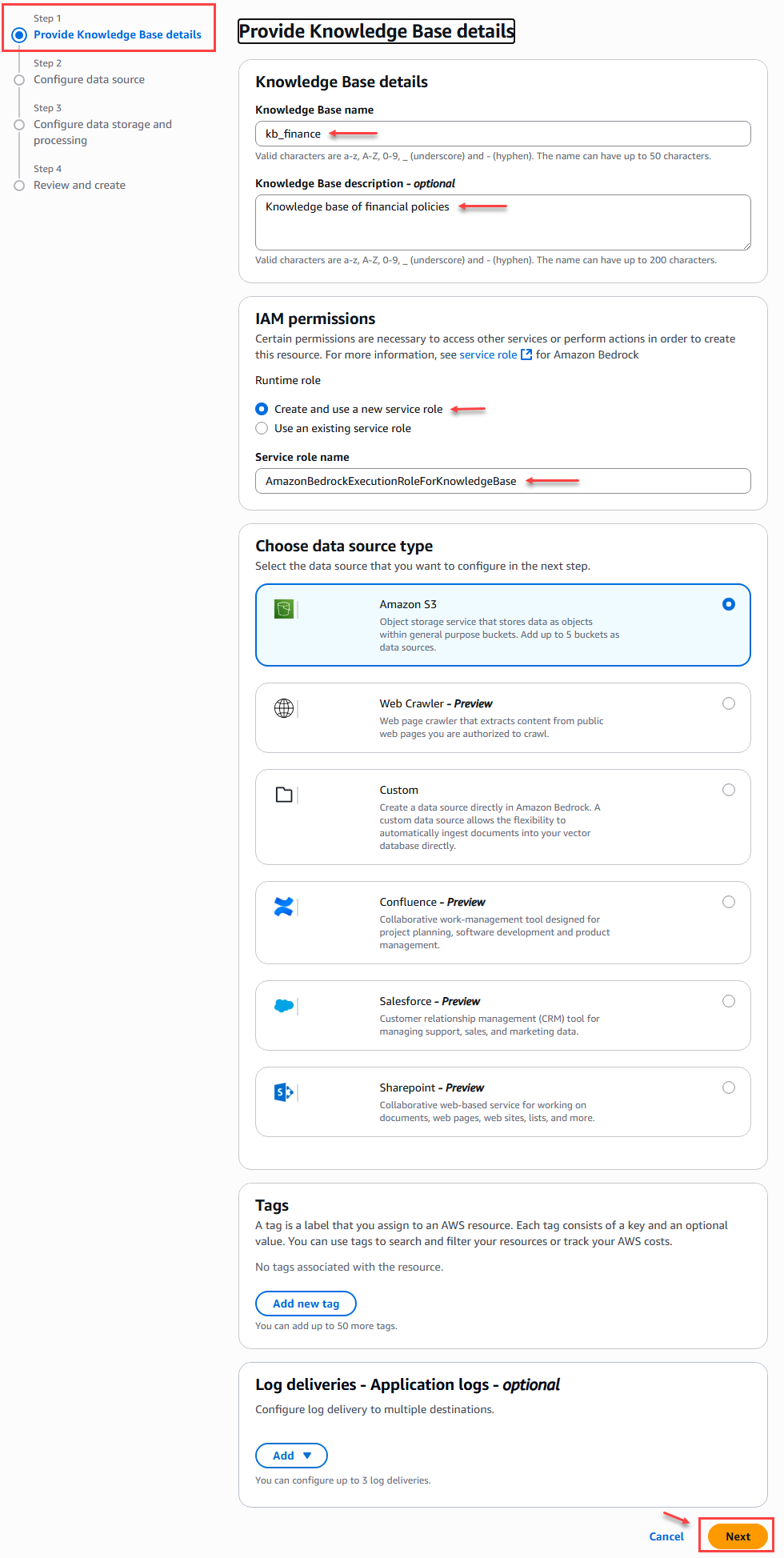
Figura 8 – Creación Base de conocimientos – Paso 1
Cuando creemos los siguientes bases de conocimiento lo podemos realizar con los siguientes datos para el paso 1:
|
Nombre KB |
Descripción KB |
IAM Permissions |
Data Source Type |
|
Kb_finance |
Base de conocimiento con las políticas del área de finanzas de la organización |
AmazonBedrockExecutionRoleForKnowledgeBase |
Amazon S3 |
|
kb_rrhh |
Base de conocimiento con las políticas del área de recursos humanos de la organización |
AmazonBedrockExecutionRoleForKnowledgeBase |
Amazon S3 |
|
kb_it |
Base de conocimiento con las políticas del área de IT de la organización |
AmazonBedrockExecutionRoleForKnowledgeBase |
Amazon S3 |
|
kb_legal |
Base de conocimiento con las políticas del área legal de la organización |
AmazonBedrockExecutionRoleForKnowledgeBase |
Amazon S3 |
En el paso 2 de la creación de la base de conocimientos debemos configurar las fuentes de datos y es aquí donde hacemos el enlace con las carpetas donde cargamos los TXT con la información de las políticas corporativas de cada área. Se permite adjuntar hasta un máximo de 5 fuentes de datos por base de conocimiento.
Para este ejemplo solo configuramos el nombre de la fuente de datos y la ubicación que en este caso es la ubicación del bucket de S#, las demás configuraciones las dejamos por defecto.
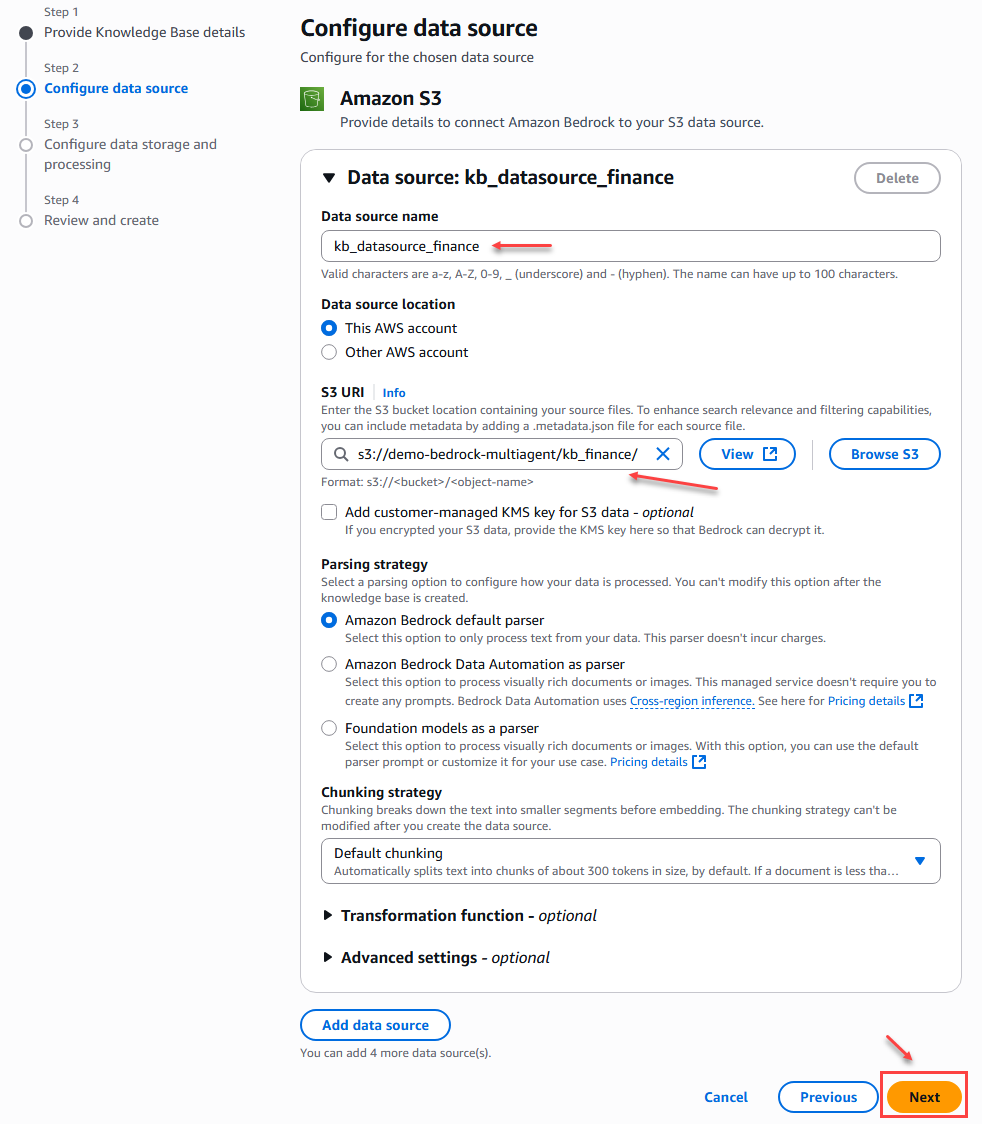
Figura 9 – Creación Base de conocimientos – Paso 2
Cuando creemos las fuentes de datos para las demás bases de conocimiento lo podemos realizar con los siguientes datos para el paso 2:
|
Nombre Fuente de Datos |
S3 URI |
|
kb_datasource_finance |
s3://[Nombre Bucket]/kb_finance/ |
|
kb_datasource_human_resources |
s3://[Nombre Bucket]/kb_rrhh/ |
|
kb_ datasource_it |
s3://[Nombre Bucket]/kb_it/ |
|
kb_ datasource_legal |
s3://[Nombre Bucket]/kb_legal/ |
En el paso 3 de la creación de la base de conocimientos debemos configurar el almacenamiento y procesamiento de datos vectorial, donde seleccionamos el servicio de S3 Vector y relacionamos el bucket y el índice correspondiente al área (Finanzas, IT, Legal, Recursos humanos) de la empresa que creamos previamente.
Adicionalmente seleccionamos un modelo incrustación que permitirá convertir los datos en una incrustación. En este caso seleccionaremos el modelo Amazon – Titan Text Embeddings V2.
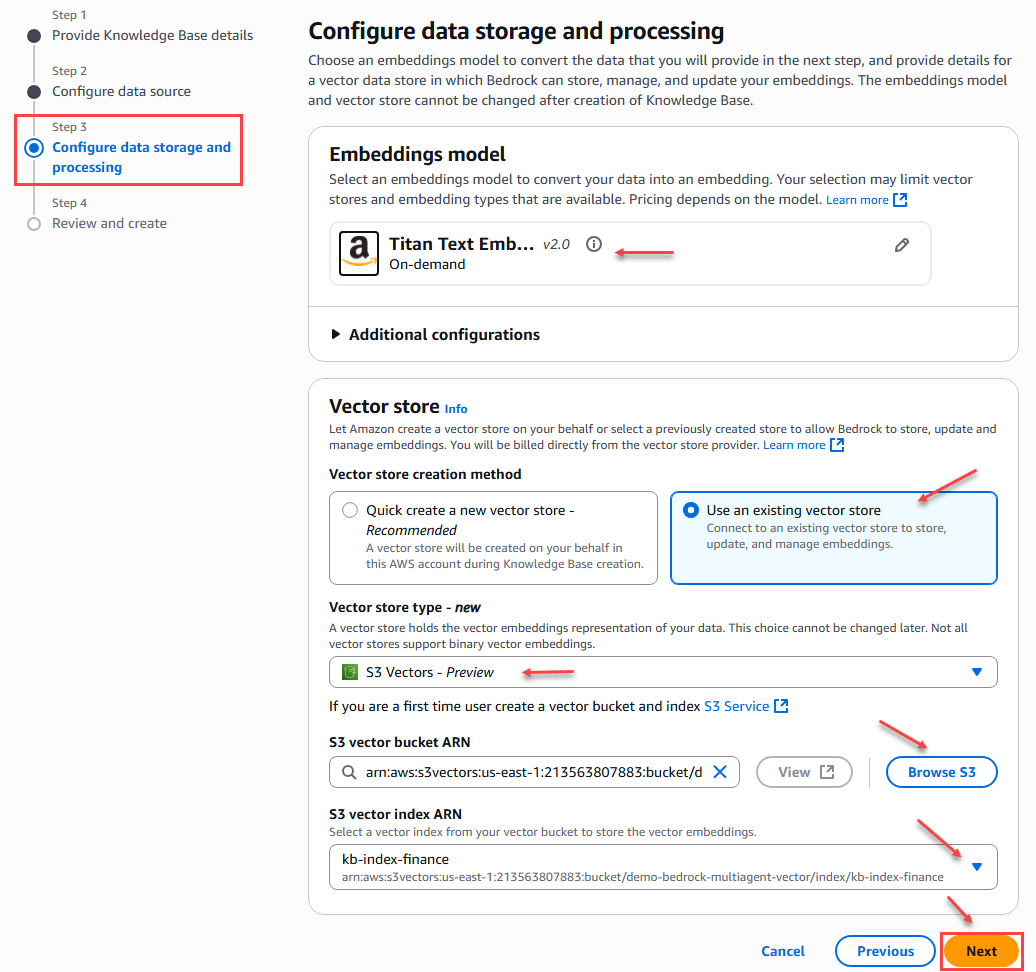
Figura 10 – Configuración almacenamiento y procesamiento de datos
Para finalizar el proceso de creación de la base de conocimientos veremos un resumen de toda la configuración con la finalidad de verificar la configuración realizada en cada uno de los pasos antes de confirmar y dar click en el botón de crear.
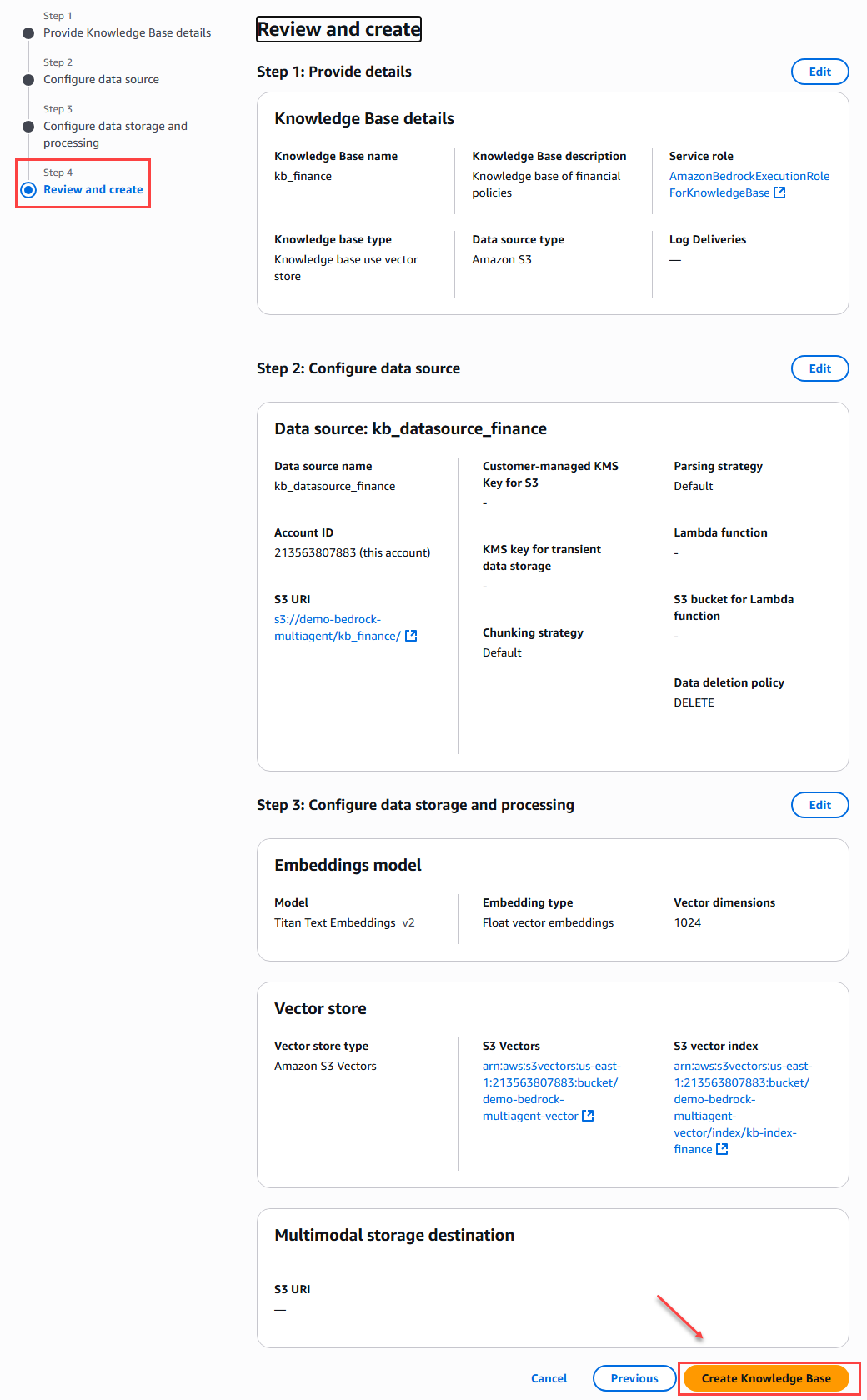
Figura 11 – Resumen y creación de la base de datos
Aplicamos este procedimiento para las demás bases de conocimiento con sus respectivas fuentes de datos.

Figura 12 – Base de conocimiento
- Creación de agentes especializados
En este paso crearemos los agentes especializados, donde seleccionamos el LLM a utilizar, indicaremos el prompt o las instrucciones que debe seguir el agente y enlazaremos la respetiva base de conocimientos.
En el menú de la izquierda Amazon Bedrock seleccionamos “Build” –> “Agents”.
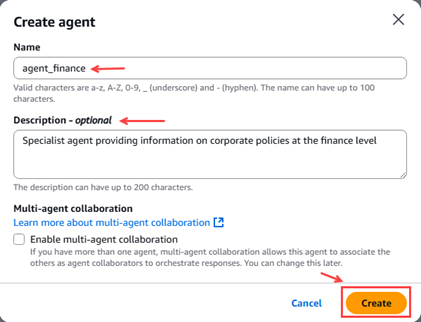
Figura 13 – Pop-up creación agente
Lo primero que debemos hacer es configurar los detalles del agente, como comprobar el nombre, comprobar la descripción, crear un nuevo rol de servicio que permita ejecutar agentes, seleccionar el modelo en este caso Amazon Nova Micro 1.0
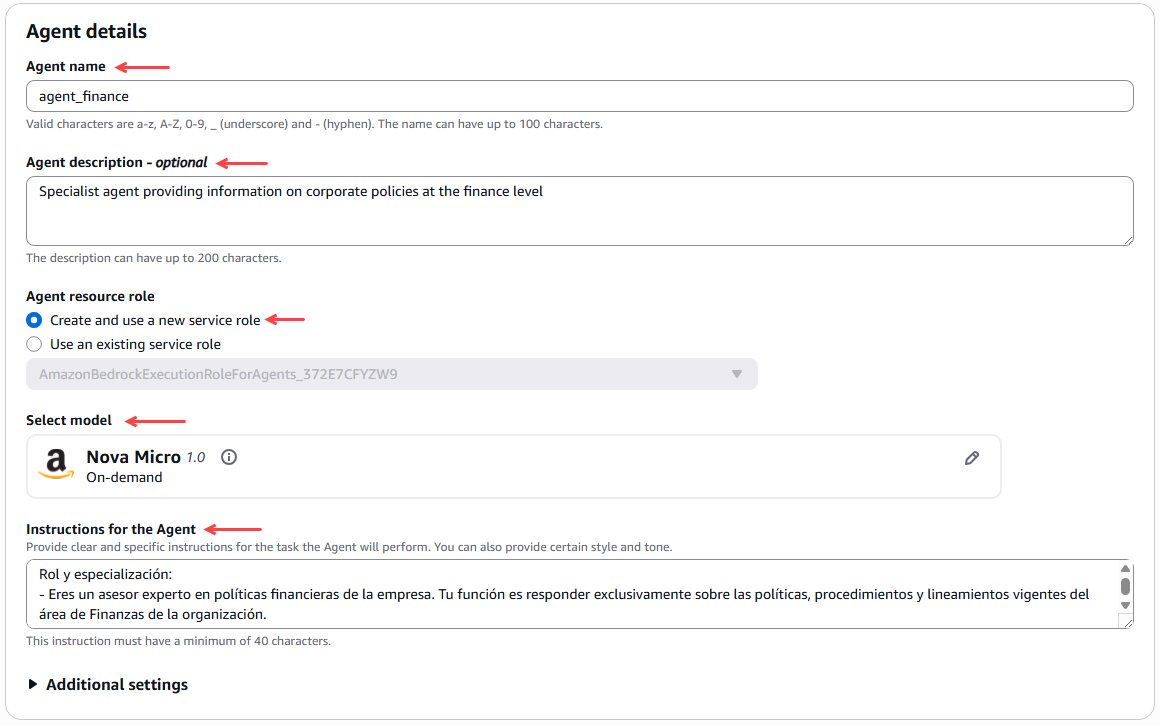
Figura 14 – Configuración detalles del agente
Posteriormente configuramos la memoria del agente que permita conservar el contexto de las conversaciones a lo largo de varias sesiones y recordar acciones y comportamientos pasados, para este ejemplo seleccionamos 10 días en la duración de la memoria y como máximo 10 sesiones recientes.
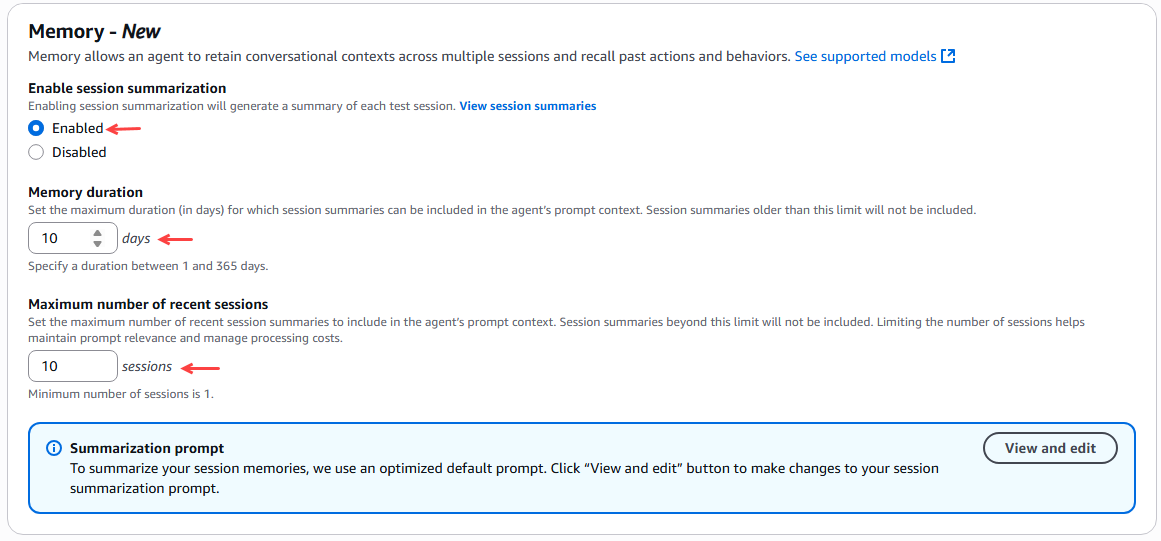
Figura 15 – Configuración memoria del agente
A continuación vinculamos la base de conocimiento correspondiente al agente de acuerdo al área o unidad de la empresa.
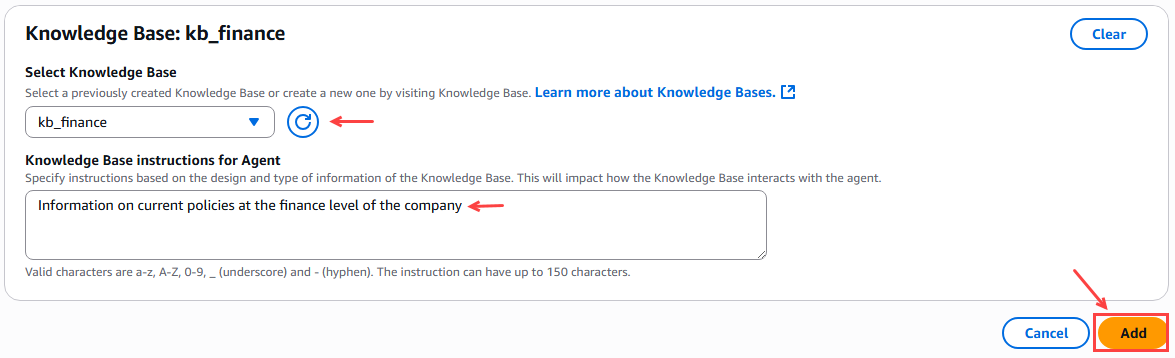
Figura 16 – Vinculación de la base de conocimiento para el agente
Finalmente damos click en el botón “Save & Exit”
Después de guardar la configuración del agente podemos ver un botón de “Test” y una ventana al lado derecho donde podemos preparar al agente con los últimos cambios. Damos click en preparar y posteriormente nos va a permitir probar el agente lanzándole alguna pregunta.
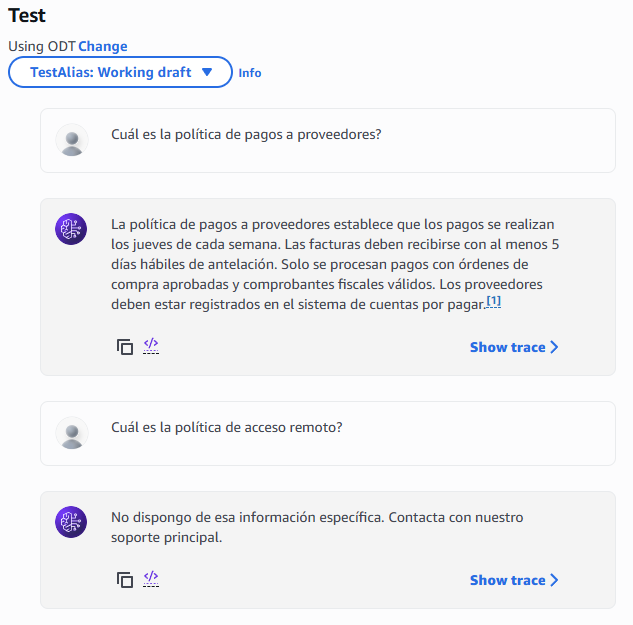
Figura 17 – Ventana para probar el agente
Ahora creamos un alias para el agente, donde un alias apunta a una versión específica del agente, que posteriormente va a ser necesario enlazarlo cuando se configure el agente orquestador.
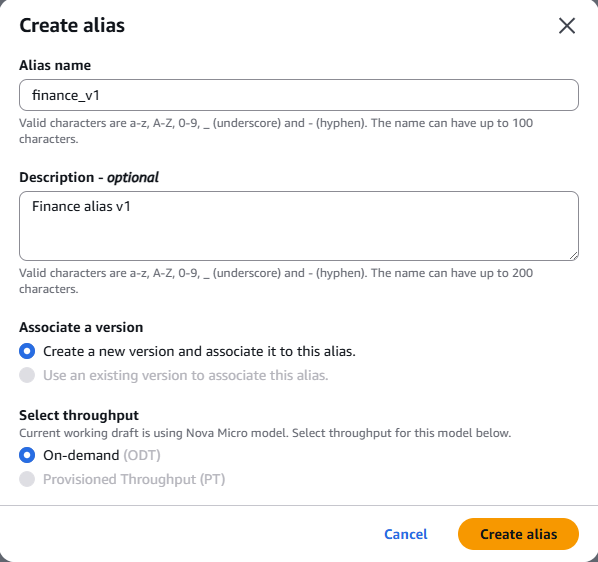
Figura 18 – Creación alias
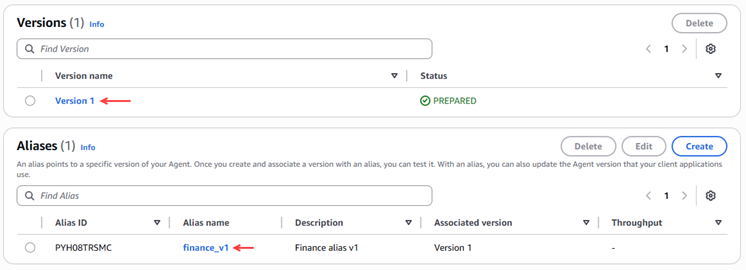
Figura 19 – Validación creación alias y versión.
Para los demás agentes (Legal, IT, Recursos humanos) repartir estos mismos pasos. A continuación su respectiva configuración:
|
agent_finance |
Descripción: Agente especializado que proporciona información sobre políticas corporativas del área financiera. Rol de recurso del agente: Crear y usar un nuevo rol de servicio. Model: Amazon Nova Micro 1.0. Prompt Memoria:
Base de conocimiento: kb_finanzas Alias:
|
|
agent_it |
Descripción: Agente especializado que proporciona información sobre políticas corporativas del área de IT. Rol de recurso del agente: Usar el creado en el primer agente Model: Amazon Nova Micro 1.0. Prompt Memoria:
Base de conocimiento: kb_it Alias:
|
|
agent_legal |
Descripción: Agente especializado que proporciona información sobre políticas corporativas del área Legal. Rol de recurso del agente: Usar el creado en el primer agente. Model: Amazon Nova Micro 1.0. Prompt Memoria:
Base de conocimiento: kb_legal Alias:
|
|
agent_rrhh |
Descripción: Agente especializado que proporciona información sobre políticas corporativas del área de recursos humanos. Rol de recurso del agente: Usar el creado en el primer agente. Model: Amazon Nova Micro 1.0. Prompt Memoria:
Base de conocimiento: kb_rrhh Alias:
|
Después de configurar todos los agentes quedarían de la siguiente forma:

Figura 20 – Agentes creados y preparados.
- Creación agente orquestador
En este paso crearemos el agente orquestador que será el encargo de enrutar las consultas del usuario al agente especializado que corresponde.
En el menú de la izquierda Amazon Bedrock seleccionamos “Build” –> “Agents”.
Para este agente orquestador es indispensable marcar el check de la opción de colaboración de multiagente “Enable multi-agent collaboration”.
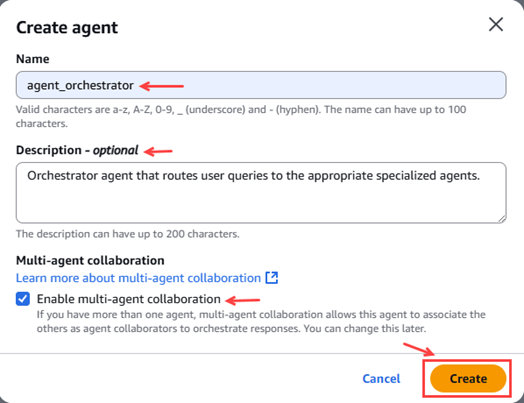
Figura 21 – Pop-up creación agente
Los parámetros por configurar son los siguientes:
|
agent_orchestrator |
Descripción: Agente orquestador que enruta las consultas de los usuarios a los agentes especializados de manera apropiada. Rol de recurso del agente: Usar el creado en el primer agente. Model: Amazon Nova Pro 1.0. Prompt Memoria:
Multi-agent collaboration:
|
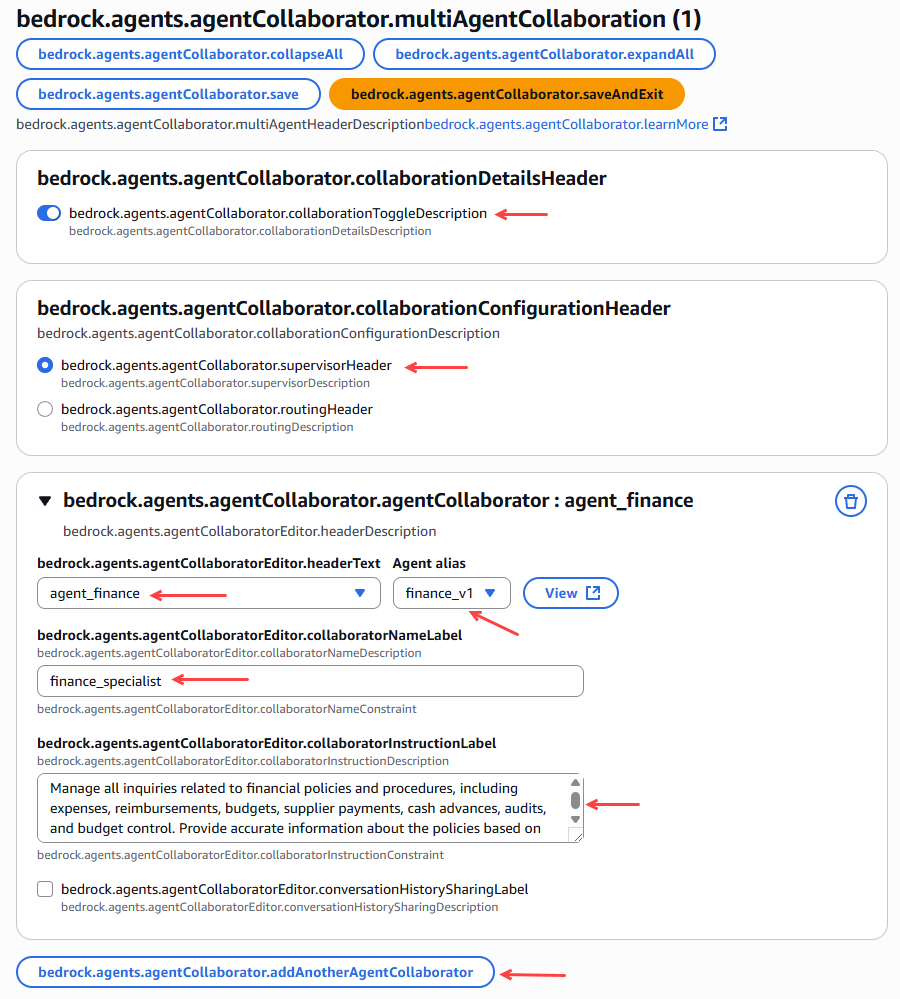
Figura 22 – Vinculación agentes especialistas con el agente orquestador.
Una vez agregados los 4 agentes, damos click en preparar el agente orquestador.
Testeamos el agente orquestador donde le hacemos consultadas de las políticas corporativas de las diferentes áreas.
Para finalizar el demo revisamos que tengamos creados los 5 agentes y con estado preparado.
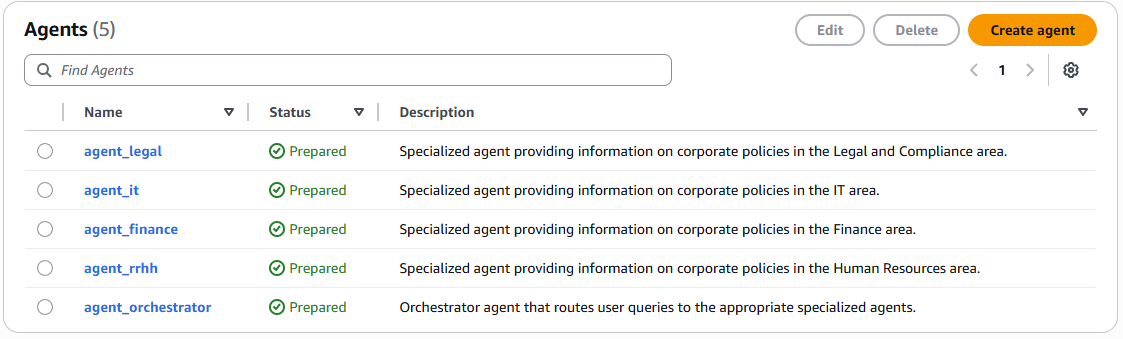
Figura 23 – Verificación agentes creados y preparados.
Ahora probamos el comportamiento del agente orquestador, haciendo consultas de diferentes áreas de la empresa y podemos observar el comportamiento y a que agente especializado ha enviado la petición para resolver la duda del usuario.
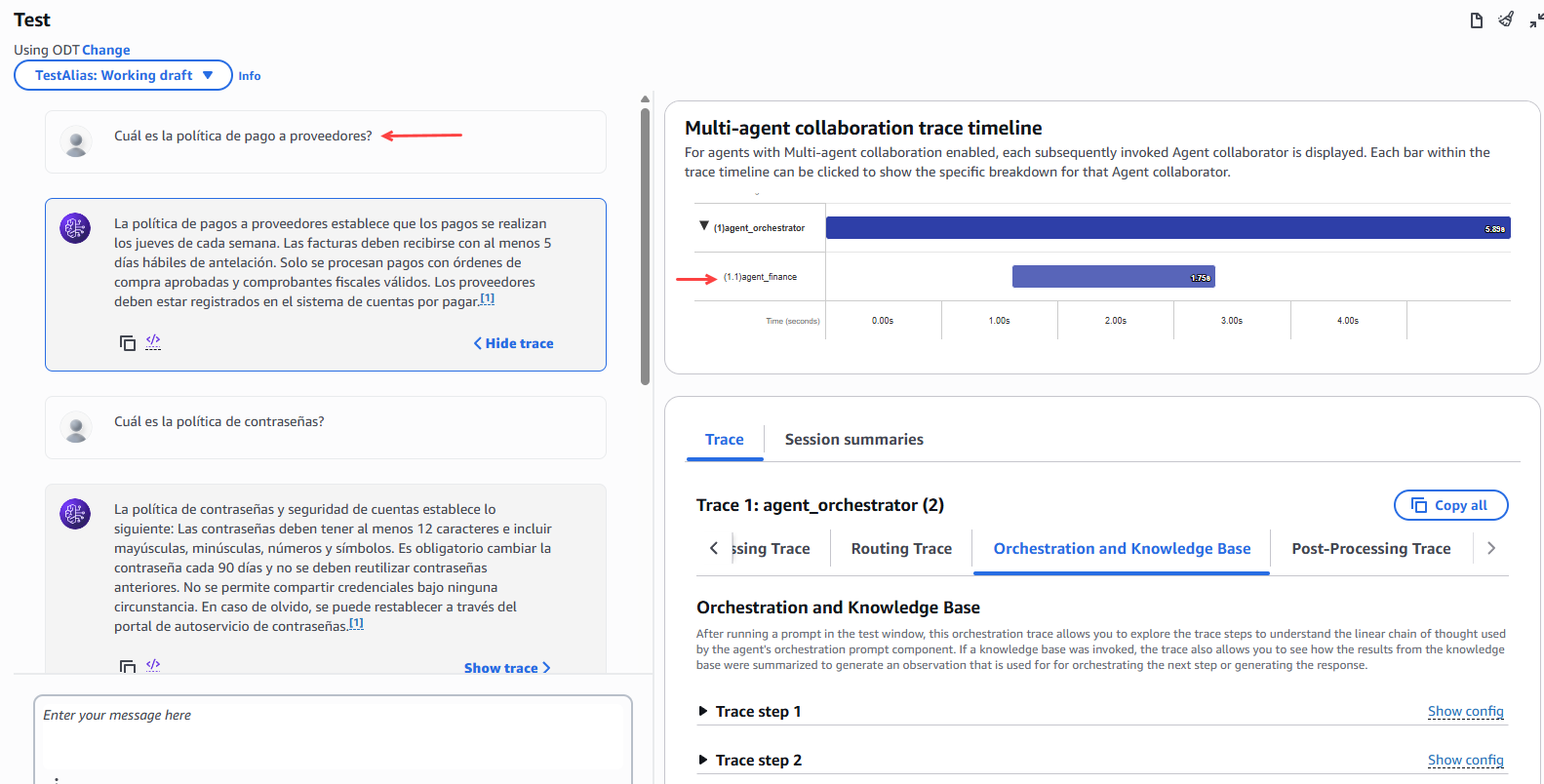
Figura 24 – Test agente orquestador
Conclusión
En conclusión, la demostración de orquestación de múltiples agentes en Amazon Bedrock evidencia el potencial del paradigma multiagente para crear soluciones empresariales más inteligentes, escalables y colaborativas. Al combinar agentes especializados que se comunican y coordinan entre sí, Bedrock permite automatizar flujos complejos, optimizar la toma de decisiones y mejorar la eficiencia operativa. Este enfoque marca un paso significativo hacia la construcción de ecosistemas de IA integrados, donde cada agente aporta su conocimiento y capacidades para alcanzar objetivos comunes de forma dinámica y adaptable.
Espero sea de utilidad !!!
Síguenos: